さくらのクラウドもAPIを公開しているので諸々の作業をプログラマブルに制御できます。
オペミスでサーバが大変なことになった時のためにディスクのアーカイブ化(バックアップ)するためのプログラムを書いたとしても、実行するための環境をクラウドの上に構築するのもいいのですが、その環境を維持運営するのはちょっと面倒。
最近流行りのサーバレスの環境で完結させるためにAWS Lambdaを使ってみました。
Lambdaは最近Pythonに対応という話が出ていたことと、curlの呼び出しに対応しているという噂を掴んたので簡単に試すには便利かなと。
ちょうど、さくらのクラウドのAPIのサンプルはcurlでサンプルコードが公開されているので、今回はコピペでやってみました;-p
サンプルコードはこちら。
https://gist.github.com/dalice/40544c999788832531c2
こちらをAWS LambdaにPythonランタイムで登録。
コードの一部を編集する必要があるので諸々準備。
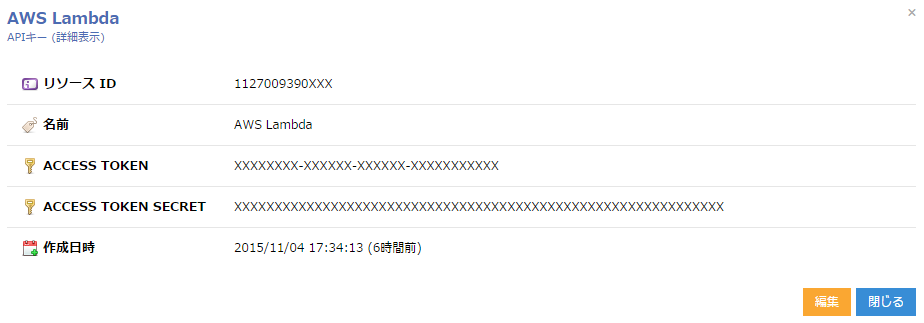
まずコード中に書かれている「access_token」 と「access_token_secret」 をクラウドのコントロールパネルのAPIキーから発行します。
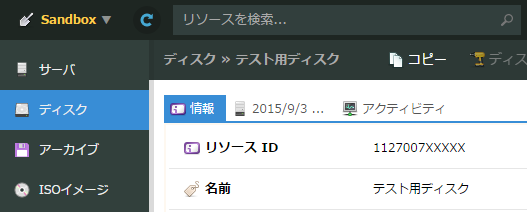
次にバックアップしたいディスクのリソースIDとディスクのあるゾーン情報を確認します。
今回はSandboxなので「zone」のところに”tk1v”と入れています。それ以外のゾーンの場合にはコメントにも書いているゾーンを記載します。
「disk_id」の部分にはディスクのリソースIDを記載します。
バックアップしたいディスクとゾーンの情報は揃えるようにしてください。
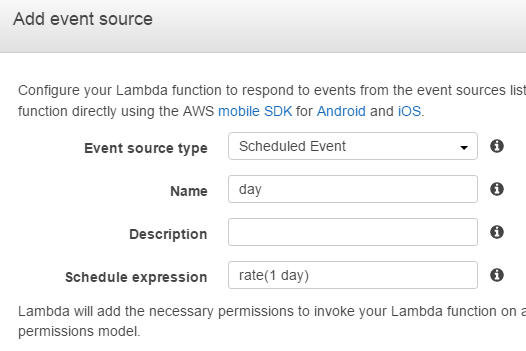
cron記法でも実行時間の記述ができるようなので厳密に処理開始を指定することも可能です。
ね、簡単でしょ。
今回はPythonからOS上のcurlコマンドを呼び出すという邪道なことしましたが、実際にはピュアPythonで記述すればもっとゴニョゴニョできると思います。
サーバにつながっているディスクの一覧を抜き出して一気にアーカイブ作成を行うとか結構実用的な気がします。
注意:
今回は例外処理とか一切していません。
あくまでも「ディスクをソースにアーカイブ作成をしろ」という命令を投げるだけです。
場合によっては命令が届かないとか、アーカイブ作成が途中で失敗するなども考えられますのでご利用の場合にはいい感じに修正してください。
あと、さくらのクラウドは使った分だけの明瞭会計ですが、AWS Lambdaは秒単位×処理能力の実課金らしいので実際にこの処理でどれだけのコストが掛かるのか分かりません。そこのところご注意を。