
たぶんこの手順のまま出来たと思います。
ちなみにローカル環境はUbuntu 8.04(virtualBox上)でHadoopのバージョンは0.19.0を利用しました。
何をしたかというとサンプルプログラムのWordCountをWikipediaのダンプデータにかけて、Amazon EC2のインスタンス数によってどの様に変化するかを確認した…というだけです。インスタンスはHadoop側から標準で立ち上げることの出来る$0.1/1時間の一番安いやつです。
Wikipediaのダンプデータはenwiki dump progress on 20081008ここの7.8GBのやつ。解凍すると39.5GBもあるので注意。
HDFSに40GB近いデータを入れ込むだけでも結構時間がかかりました。
実際にインスタンスの数を5・10・15・19(DataNodeのことね)と変化させた場合のグラフは下記のようになりました。
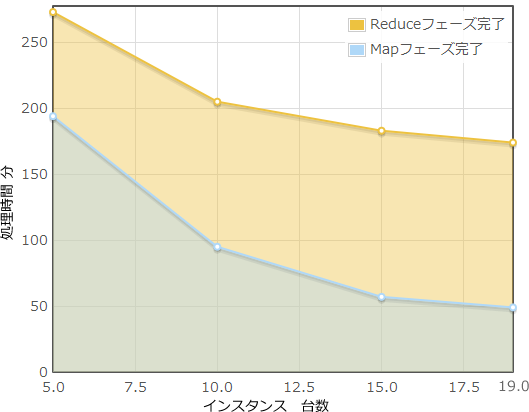
最後が19台なのはNameNodeとして1台を確保しているので、初期設定だとAmazon EC2は1度に20台までしか利用できません。どうやって解除するのかな?
と言うか40GB程度の処理なら1分程度で完了してくれるかと思っていましたが、5台なら273分、19台で174分もかかったのは衝撃的。データのソートに比べれば確かに複雑ですが、ちょっとばかり時間がかかりすぎな気もします。
あと、15台から19台に変化させた時に処理時間の減少があまりなかった(10分程度)のが気になる。ここら辺何故なんでしょうか?
何らかの参考になれば幸いです。
次は自分で何かしらのデータを処理させたいです:p